こないだX(旧Twitter)でこんなポストを見かけました。
私の顔、「も」とか「ぬ」って感じ
— ガン.D.エン (@kirokiromanga) February 8, 2024
「き」とか「さ」みたいな顔になりたい
このポスト見てて思いました。
これ数えたら、みんなの今の顔となりたい顔をどう思っているかわかりそう!って。
顔タイプ診断ってあるじゃん? あれのカジュアルな感じと言えそうです。
しかもひらがなになぞらえることが顔タイプ診断と違うのは、ひらがなは歌詞と同じく文字であるということ。
ということは、今の自分の顔に近い歌詞や、なりたい自分に近い歌詞、みたいなものが取り出せるのでは?とも思いました。
きょうはそういう実権をしました!という話です。
結論を先取りします。うまくいってません!
みんなのなりたい顔を教えて!
というわけで、このポストについているリプライと引用リポストを確認して、記載されているひらがなをカウントしていきます。
その際、「今の顔」「なりたい顔」の2つに分けて収集しました。
たいていSNSでテキストを収集するときって「もかな〜〜」みたいなどっちだよ!ってなるポストが多く寄せられがちなのですが、今回は顔をひらがなになぞらえるという新規性があるおかげなのか、わかりづらいポストがほとんどありませんでした。
ひとりのひとが複数のひらがなを投稿している場合でも重みは同じで1文字単位で見ていきます。「な行」って書いてあったら「なにぬねの」全てをカウントします。
インプ(レ)ゾンビは目視で除外して、今回は116ポストを対象にしました。
こういうタイプの表ができました。
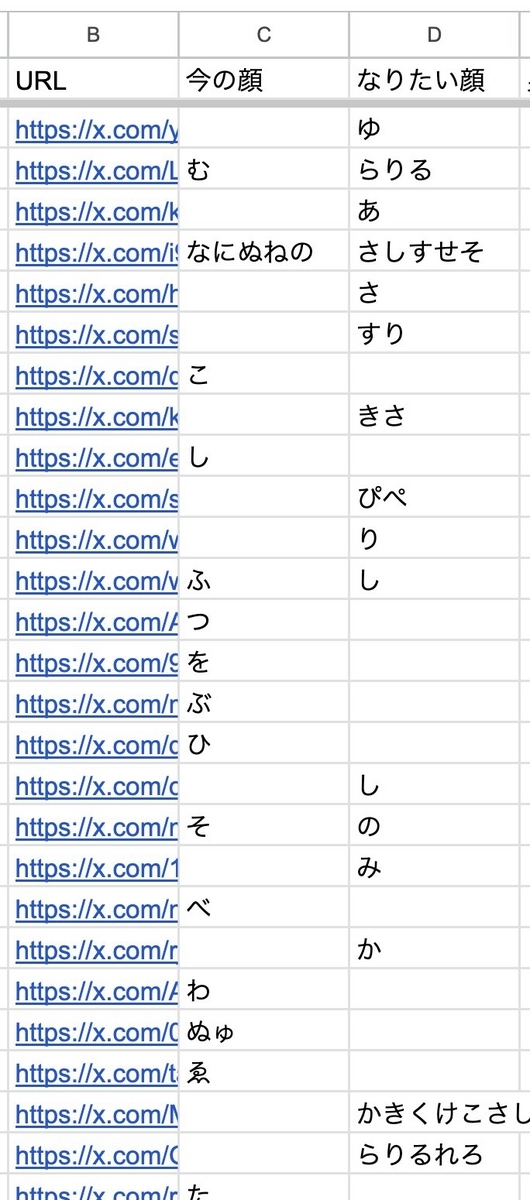
それを文字単位で数えていきます。
Googleスプレッドシートでなら対象セルをすべてTEXTJOINしたあとで、今度は文字単位で分割するのがよいですね。
集計するとこういう感じになりました。
リプと引用を取れるだけ取って、今の顔となりたい顔のひらがなをそれぞれカウントしてみました!
— ハコサト📦 (@hacosato) February 11, 2024
今の顔は「ぬむもふの」って感じでもったりした音が多いかも…
なりたい顔は「すさりるら」って感じでもっと軽やかっぽい✨
母音と子音でそれぞれ見るとその傾向がはっきりしますね!! https://t.co/TqYUT5l9BS pic.twitter.com/4vgkSNUPqE

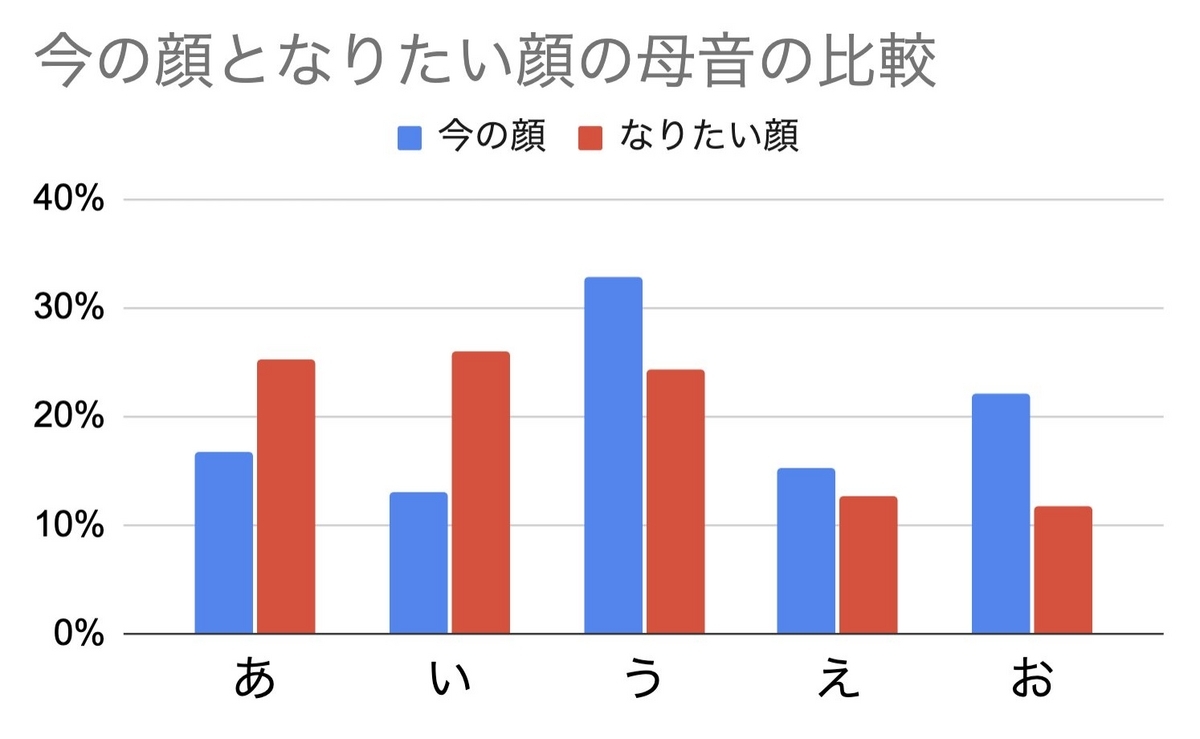

ポストに書かなかった点も追記すると、下記のような特徴があると思います。
- 母音の観点では「あ」と「い」が今の顔に多くて、「う」「え」「お」はなりたい顔に多め。「う」はなりたい人気も高いとも言えるので、母音三角形の中で際立ったはっきりした顔に憧れがあるかも。
- 見た感じ、舌の前後や高低による好みの違いは薄そうな感じ。
- 子音でいうと「な行」と「ま行」が今の顔に多くて現状には明らかに鼻音という共通点が。
- なりたい顔は「さ行」「ら行」に集中しているけど音声的な共通点は薄い組み合わせ。なりたい顔は一様ではなくて好みがあるのかも。
- 「さ行」「ら行」は両方歯茎音ではあるけど、ほかにも「た行」や「な行」も歯茎音なのに人気が出ていないから調音位置は人気に関係なさそう。
- てか「た行」は今の顔にもなりたい顔にもぜんぜん登場しなくて意外。わりと想起しやすいひらがなだと思うけどそんなことないんか。
- 思った通り濁音は「なりたい顔」にはほとんど出てこない。
って感じ! 調べておもしろかったです!!
今の顔、なりたい顔に近い楽曲はなーんだ?
さて、ここでパラメータ数50個ぐらいのお手ごろサイズの特徴量のデータが2つ手に入りました。
ここにサンプルを追加することによって、(古典的)機械学習やデータサイエンスができそうな感じがします。やってみよ!
ということで、今回はHoneyWorksの楽曲を追加してみることにしました。
HoneyWorksといえば『可愛くてごめん』って曲があります。
自分の味方は自分でありたい。
って動画の概要欄にあるように、今回の調査で言うところのなりたい顔側を描いていると言えそうです。
一方で『可愛くなれたらいいのに』という曲もあり、こちらは最終的には自分の可愛さを認める方向で着地するものの、どちらかというと好きになれない自分と向き合うことが主眼の曲です。
『可愛くなれたらいいのに』は今回の調査で言うところの今の顔側を描いていると言えそうです。
こんな風にHoneyWorksは今の顔となりたい顔、の2つの面を描いた曲が多そうだと思ったので、調査に加えてみることにしました。
Python使って書いてて、importだけお見せするとこういう感じのを使いました。
import MeCab import jaconv import unicodedata import numpy as np import pandas as pd import sqlite3 import matplotlib.pyplot as plt import sklearn
まず歌詞を持ってきて、MeCabに読ませてかなにします。表記ではなくて発音でかなをふりたい(「公園」は「こうえん」ではなくて「こーえん」と発音するし、今回の調査の目的に照らすと長音いらないかと思ったから「こえん」で扱いたい)ので、UtaTenにあるようなルビは使いませんでした。MeCabの読み誤りは修正していません。
このうち名詞だけを調査対象としました。活用する動詞や形容詞を入れると活用語尾に多く含まれるひらがなに引っ張られそうなので。
そうするとパラメータはひらがなの数だけ、サンプル数は曲の数だけの表ができます。78列、63行です。
これに先ほど出した今の顔、なりたい顔を追加して78列65行のデータとし、これを主成分分析で2次元に圧縮して散布図を描きます。
こういう感じ!
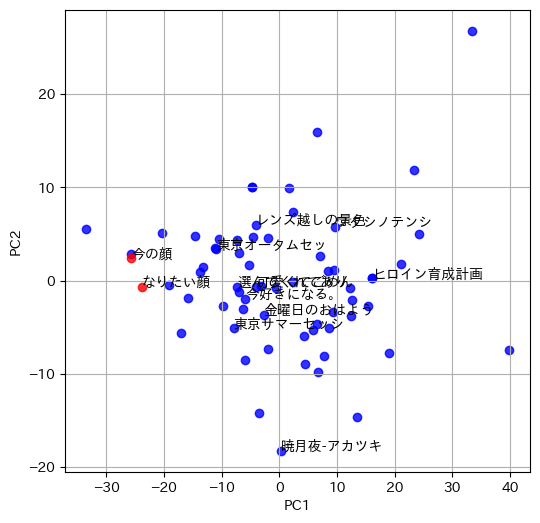
最初はわーやったー!!って思いました。
けど、よく見るとこれあんまりおもしろい結果ではありません。
今の顔となりたい顔の距離が近すぎて、分類するのに向いてないと思うんですこれだと。
いちおう第一主成分と第二主成分における観測変数の寄与度をプロットするとこういう感じ。

これだとたとえば「い」が入るときに第一主成分がプラスに働きやすいことが示されています。
だけど「い」は今の顔で1票、なりたい顔で0票しか入っておらず、全体の票数が3ケタの調査であることを考えると分類に向いているパラメータではないと考えられます。
今後の課題
いまわかる範囲では2段階あると思うんです。
ひとつは主成分分析。
これは持っているデータの特徴全体をできるだけ残したまま次元を減らすことができる手法だと考えていますが、今回わたしが主に残したいのってデータ全体ではなくて今の顔となりたい顔の2つなんですよね〜。
その違いが際立つように次元を減らす方法があるのかな〜というのがひとつ知りたいこと。この2つのデータだけを使って主成分分析をした後、残りの楽曲のデータを同じ係数でマッピングし直すみたいなことをすればいいの?🤔 そんなことしちゃダメ?
もうひとつは少し遡ってパラメータの作り方。今回はひらがなすべてを対等に扱いましたが、音韻論での音声素性に還元する方が特徴を端的に表せている可能性があります。
特に子音でいうと「なりたい顔はさ行」みたいに子音全体を指定したポストが割とありました。その人の中ではさ行の中にある無声性や摩擦音性が魅力的なのかもしれません。
音声素性はいろんな流派があって今回何が向いているのかよくわからないという欠点があります。有声性、鼻音性、唇音性、共鳴性あたりが効いてそうな感じするけど、いっぱい素性持ってくるしかないのかなぁ〜。
あと、そもそもの研究の組み立てがおかしい可能性もあります。わたしは今回分類したい2つのカテゴリーを楽曲のデータに混ぜ込んで対等に扱っているものの、ふつうこういうことするんだっけ?という疑問があります。これって半教師あり機械学習って扱いでいいの?そういうときってふつうどうするの?
この辺りを今後学んでいかないともっと高みに立てない! 立ちたいよ高みに!